ProsodyPro * ---- A Praat script for large-scale systematic analysis of continuous prosodic events (Version 5.7.9: What's new?) [Download]
by Yi Xu
The beta version ( 6.1.3 ) allows users to leave individual sentences in the original recording, without extracting them to separate sound files. However, the beta version has not been updated lately and so lacks many of the new features of the standard version. Please use it with caution.
An interactive Praat script that allows you to:
- Get accurate f0 tracks using a method that combines automatic vocal pulse marking by Praat, manual correction by yourself, a trimming algorithm that removes spikes and sharp edges (cf. Appendix 1 in Xu 1999), and a triangular smoothing function
- Get continuous f0 velocity (= first derivative of f0) curves (for labeled intervals only)
- Segment and label intervals for each sound (.wav) file
- Cycle through all sound files in a folder without using menu commands
- Get time-normalized f0 (for labeled intervals only) (cf. Xu 1997), f0 velocity and intensity. Useful if you want to plot these curves averaged** across multiple repetitions of the same word or sentence
- Get time-normalized f0, f0 velocity and intensity with original time preserved (cf. Xu & Xu 2005). Useful if you want to plot these curves with averaged original time for each interval
- Get rectified, trimmed f0 as PitchTier objects which can replace the pitch tier in Manipulation objects
- Get sampled f0 (for labeled intervals only) -- f0 at fixed time intervals as determined by F0_sample_rate (number of points per second)
- Get maxf0, minf0, excursionsize(st), meanf0, mean intensity, duration, max velocity, final velocity, final f0, meanintensity, Maxf0_loc_ms and Maxf0_loc_ratio from each labeled interval
- Get results in ensemble files: normf0.txt, normIntensity, samplef0.txt, f0velocity.txt, maxf0.txt, minf0.txt, excursionsize.txt meanf0.txt, maxvelocity.txt, duration.txt, finalvelocity.txt, finalf0.txt, meanintensity.txt, maxf0_loc_ms.txt and maxf0_loc_ratio.txt
- Get mean_normf0.txt, which contains meanf0 contours averaged** across repetitions of identical sentences
- Get mean_normf0_cross_speaker.txt, which contains meanf0 contours averaged** across identical sentences produced by multiple speakers
Motivation and brief history
ProsodyPro is developed as a convenient tool for our own research. It allows us to systematically process large amount of speech data with high precision. It has maximally reduced the amount of human labor by automating tasks that do not require human judgment, such as locating and opening sound files, taking measurements, and saving raw results in formats ready for further graphical and statistical analysis. On the other hand, it also allows human intervention of processes that are prone to error in automatic algorithms such as pitch detection and segmentation.
The f0 trimming and time-normalization algorithms, which are part of the core of the script, were developed in my PhD research (Xu 1993), which were then implemented in a C program working in conjunction with xwaves, which, like Praat, generates automatic vocal cycle markings and saves most of the human labor in marking the cycles manually as done in my dissertation. The arrival of Praat, thanks to the brilliant invention of Paul Boersma and David Weenink, makes it possible to put these algorithms together in a single script that can run on all major computer platforms. It also solved the problem of having to write a different C program for each new experiment.
The first version of the script was made public in 2005. Since then it has been used in a growing number of research projects. Some are listed here.
Why time-normalization? -- Justifications you may need when responding to questions
- First, time-normalized contours are generated only for the purpose of making graphical comparisons. The specific measurements also generated by ProsodyPro, such as maxf0, minf0, meanf0, etc., are all taken from non-time-normalized contours. So, nothing is lost when time-normalized contours are presented in addition to the specific measurements.
- Second, in the common practice of reporting only specific measurements, the readers are always left wondering what the rest of F0 contours might look like. There are of course occasional presentation of full f0 contours of exemplary sentences, but one can never be sure how representative they are. Time-normalization allows the averaging of f0 contours across repetitions and even speakers, thus removing most of the random variations while retaining full details of continuous f0 contours, leaving little to guesswork. If there is a concern that averaging across speakers may hide individual differences, one can always decide to average only across repetitions and present speaker-specific contours separately.
- Third, a major advantage of time-normalization is that it allows us to clearly see the locations and manners of the maximum differences between experimental conditions by plotting the mean f0 contours in overlaid graphs, like those shown below. This in turn allows us to find measurements that potentially best reflect the real differences between experimental conditions.
- Fourth, it is not the case that time-normalization carries more assumptions than other forms of data presentation. When reporting only a single measurement, say, maxf0, from a syllable or word, the assumption is that maxf0 is fully representative of the f0 of that syllable or word. If measurements are taken from fixed or relative time points in a domain, e.g., in the middle, near the beginning and the end, or three points evenly spaced in the domain, this is also time-normalization. But this gives us the maximum time resolution of 1-3 points per domain. The default time resolution in ProsodyPro, in contrast, is 10-points per domain.
- Finally, time-normalization does carry assumptions, of course. When using the syllable as the domain of normalization, for example, the assumption is that speakers produce syllable-sized contours consistently (see Xu & Wang 2001 and Xu & Liu 2006 for some empirical basis). But ProsodyPro also allows the use of other units, e.g., words, or even phrase, as the normalization domain, if the assumption is indeed that speakers produce word-sized or phrase-sized f0 contours consistently.
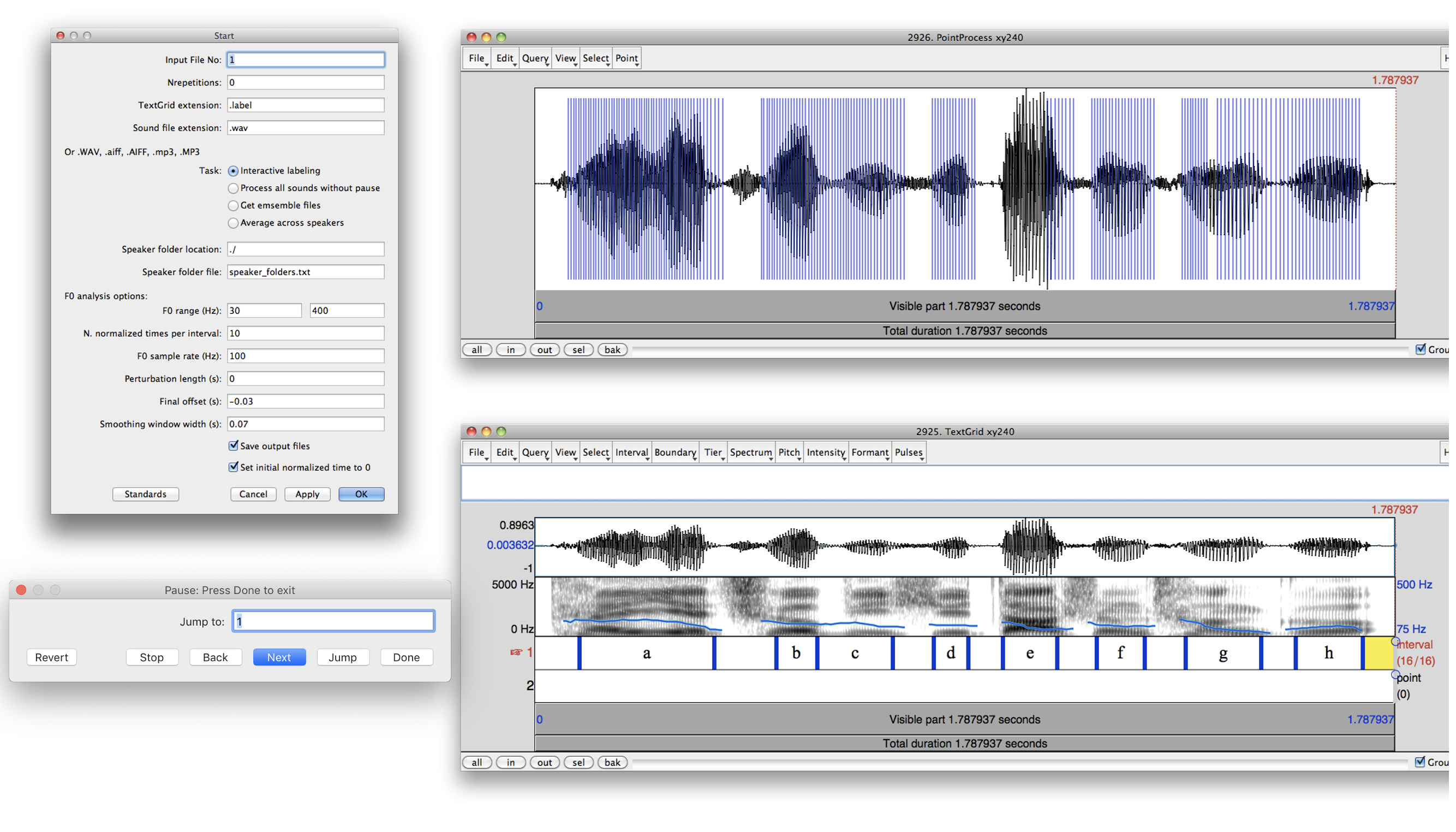
Instructions (中文说明请看这里)
- Put ProsodyPro.praat in the folder containing the sound files to be analyzed, and launch Praat;
- Select Open Praat Script... from the top menu;
- Locate ProsodyPro.praat in the dialogue window and select it;
- When the script window opens in Praat, select Run from the Run menu (or type the key shortcut command-r or control-r);
- In the startup window, check or uncheck the boxes according to your need, and set appropriate values in the text fields or simply use the default values. Select the task by checking the appropriate radio button.
- Click OK and three windows will appear. The first window (Pause) controls the progression of the analysis:
Next = Bring up the next sound to be analyzed
Back = Go back to the previous sound
Jump = Open the sound indicated in the "Jump to" box. The sound number can be found in "FileList.txt" in the current folder.
Done = Save the current annotation and close all the windows
Stop = Close all the windows without saving the current annotation
- To end the progression of the current analysis session, press "Done" in the Pause window, and the last sound analyzed will be shown in the Praat Info window. You can use that number as a starting point in you next analysis session.
- The second window (TextGrid) displays the waveform and spectrogram of the current sound together with optional pitch track and formant tracks in the spectrogram panel, and vocal pulse marks in the waveform panel. (These tracks and marks cannot be manually changed. So you can hide them to reduce processing time by using the corresponding menu.)
- At the bottom of this window are two TextGrid tiers, where you can insert interval boundaries (Tier 1) and add comments (Tier 2). For any interval that you want to have results saved, a label in Tier 1 is required. The label can be as simple as a, b, c or 1, 2, 3.
- The third window (PointProcess) displays the waveform together with vocal cycle marks (vertical lines) generated by Praat. This is where you can manually add the missing marks and delete the redundant ones. You need to do this only for the named intervals, as explained next.
- After processing individual files, you can run the script again to get ensemble files by checking the third radio button from the top.
- You can also change various parameter after processing individual files by runing the script again with the radio button "Process all sounds without pause" checked. Just watch the script run through all the files on its own.
- You can also generate mean normf0 contours averaged** across repetitions of identical sentences. To do this, set the value of Nrepetitions in the opening window according to the number of repetitions in your data set when you run the script with the "Get ensemble files" button checked. Make sure that the number of labeled intervals are identical across the repetitions.
- To force ProsodyPro to skip extra repetitions, you need to check "Ignore extra repetition" and also name your sound files with a final digit that indicates repetition.
- To average across unequal number of repetitions, you can create a text file (default = repetition_list.txt) in which sound-file names are listed in a single column, with blank lines separating the repetition groups. You can create this file by renaming "FileList.txt" that is always generated by ProsodyPro, and then modifying it by inserting blank lines and deleting sounds that you want to exclude. Note that deleting sound names in this file allows you to skip sounds that you want to exclude in your final analysis.
- You can also generate mean normf0 contours averaged** across speakers. To do this, first create a text file (speaker_folders.txt) containing the speaker folder names arranged in a single column. Then run ProsodyPro with the 4th task--Average across speakers--checked. The script will read mean_normf0.txt from all the speaker folders, average the f0 values on a logarithmic scale, and then convert them back to Hz. The grand averages are saved in "mean_normf0_cross_speaker.txt". In the Start window, you also need to tell ProsodyPro where the speaker folder file is. The default location is the current directory: "./". If it is in an upper directory, you should enter "../"
Troubleshoot
- By far the most common problems are caused by special symbols like spaces and hyphens in your file names or file paths (folder names). Please make sure your file and folder names consist of only letters, numbers and underscore, e.g., my_sounds/speaker1/sentence_A1.wav.
Output
Each time you press "Continue" in the Pause window, various analysis results are saved for the current sound as text files:
- X.rawf0 (Hz) -- raw f0 with real time computed directly from the pulse markings
- X.f0 (Hz) -- smoothed f0 with the trimming algorithm (Xu, 1999)
- X.samplef0 (Hz) -- f0 values at fixed time intervals specified by "f0 sample rate"
- X.smoothf0 (Hz) -- samplef0 f0 smoothed by a triangular window
- X.timenormf0 (Hz) -- time-normalized f0. The f0 in each interval is divided into the same number of points (default = 10).
- X.timenormIntensity (dB) -- time-normalized intensity. The intensity in each interval is divided into the same number of points (default = 10).
- X.actutimenormf0 (Hz) -- time-normalized f0 with each interval divided into the same number of points (default = 10). But the time scale is the original, except that the onset time of interval 1 is set to 0, unless the "Set initial time to 0" box in the startup window is unchecked.
- X.f0velocity (semitones/s) -- velocity profile (instantaneous rates of F0 change) of f0 contour in semitone/s at fixed time intervals specified by "f0 sample rate" ***
- X.means -- Containing the following values (in the order of the columns):
- maxf0 (Hz)
- minf0 (Hz)
- meanf0 (Hz)
- excursion size (semitones)
- finalf0 (Hz) -- Indicator of target height (taken at a point specified by "Final offset" in the startup window)
- mean intensity (dB)
- duration (ms)
- max_velocity (semitones/s)
- final_velocity (semitones/s) -- Indicator of target slope (taken also at a point earlier than the interval offset by time specified by "Final offset" in the startup window)
- maxf0_loc_ms -- Time of the f0 peak relative to the onset of an interval in milliseconds
- maxf0_loc_ratio -- Relative location of the f0 peak as a proportion to the duration of the interval
If you want to change certain analysis parameters after processing all the sound files, you can rerun the script, set the "Input File No" to 1 in the startup window and check the button "Process all sounds without pause" before pressing "OK". The script will then run by itself and cycle through all the sound files in the folder one by one.
After the analysis of all the individual sound files are done, you can gather the analysis results into a number of ensemble files by running the script again and checking the button "Get ensemble results" in the startup window. The following ensemble files will be saved:
- normf0.txt (Hz)
- normtime_semitonef0.txt (semitones)
- normtime_f0velocity.txt (semitones/s)
- normtimeIntensity.txt (dB)
- normactutime.txt (s)
- maxf0.txt (Hz)
- minf0.txt (Hz)
- excursionsize.txt (semitones)
- meanf0.txt (Hz)
- duration.txt (ms)
- maxvelocity.txt (semitones/s)
- finalvelocity.txt (semitones/s)
- finalf0.txt (Hz)
- meanintensity.txt (dB)
- samplef0.txt (Hz)
- f0velocity.txt (semitones/s)
- maxf0_loc_ms.txt (ms)
- maxf0_loc_ratio.txt (ratio)
If Nrepetitions > 0, the following files will also be saved:
- mean_normf0.txt (Hz)
- mean_normtime_semitonef0.txt (semitones)
- mean_normtime_f0velocity.txt (semitones/s)
- mean_normtimeIntensity.txt (dB)
- mean_normactutime.txt (s)
- mean_maxf0.txt (Hz)
- mean_minf0.txt (Hz)
- mean_excursionsize.txt (semitones)
- mean_meanf0.txt (Hz)
- mean_duration.txt (ms)
- mean_maxvelocity.txt (semitones/s)
- mean_finalvelocity.txt (semitones/s)
- mean_finalf0.txt (Hz)
- mean_meanintensity.txt (dB)
- mean_maxf0_loc_ms.txt (ms)
- mean_maxf0_loc_ratio.txt (ratio)
If Task 4 "Average across speakers" is selected, the following file will also be saved:
- mean_normf0_cross_speaker.txt
- mean_normactutime_cross_speaker.txt
- mean_normtime_f0velocity_cross_speaker.txt
- mean_normtime_semitonef0_cross_speaker.txt
BID (Bio-informational Dimensions) meansurements
A set of emotion-relevant measurements have been added since version 5.6. These measurements were proposed in Xu, Kelly & Smillie (2013). based on Morton, 1977, Ohala, 1984, as well as our own experimental work.
- h1-h2 (dB) -- Amplitude difference between 1st and 2nd harmonics
- h1*-h2* (dB) -- Formant-adjusted h1-h2 (Iseli, Shue & Alwan 2007)
- H1-A1 (dB) -- Amplitude difference between 1st harmonic and 1st formant
- H1-A3 (dB) -- Amplitude difference between 1st harmonic and 3rd formant
- cpp -- Cepstral Peak Prominence (Hillenbrand et al., 1994)
- center_of_gravity (Hz) -- Spectral center of gravity
- Hammarberg_index (dB) -- Difference in maximum energy between 0-2000 Hz and 2000-5000 Hz
- energy_below_500Hz (dB) -- Energy of voiced segments below 500Hz
- energy_below_1000Hz (dB) -- Energy of voiced segments below 1000Hz
- Formant_dispersion1_3 (Hz) -- Average distance between adjacent formants up to F3
- F_dispersion1_5 (Hz) -- Average distance between adjacent formants up to F5
- median_pitch (Hz) -- Median pitch in Hertz
- jitter -- Mean absolute difference between consecutive periods, divided by mean period
- shimmer -- Mean absolute difference between amplitudes of consecutive periods, divided by mean amplitude
- harmonicity (dB) -- Harmonics-to-Noise Ratio (HNR): The degree of acoustic periodicity
- energy_porfile (dB) -- Fifteen signal energy values computed from overlapping spectral bands of 500-Hz bandwidth: 0–500, 250–750, 500–1000, ... 3250–3750, 3500–4000
Note that you can generate the ensemble files only if you have analyzed at least one sound following the steps described earlier.
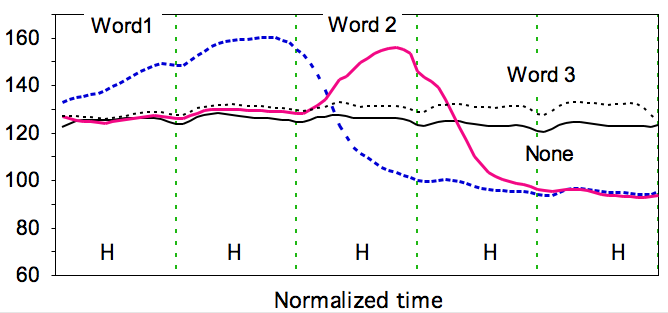
Examples
The following examples show how functional contrasts can be easily brought out by time-normalized f0 contours, whether plotted on normalized time or mean time.
 _ _
_ _
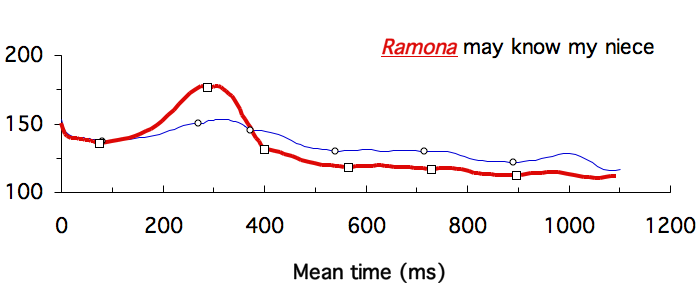
_ _ _ _ _ _ _ _ _ _ Data from Xu (1999) _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ Data from Xu & Xu (2005)
Download
- Press here to download a zip archive containing a single text file. The script should be able to run under Mac, Windows or Unix.
Need more help?
Detailed instructions can be also found at the beginning of the script.For more information, take a look at FAQ, and if you are still stuck, please write me (yi.xu at ucl.ac.uk).
Bug reports, suggestions on improvement and new features are also welcome.
How to cite
Xu, Y. (2013). ProsodyPro — A Tool for Large-scale Systematic Prosody Analysis. In Proceedings of Tools and Resources for the Analysis of Speech Prosody (TRASP 2013), Aix-en-Provence, France. 7-10.
Published research making use of ProsodyPro (or its predecessor TimeNormalizeF0)
- Ambrazaitis, G. and Frid, J. (2012). The prosody of contrastive topics in Southern Swedish. In Proceedings of FONETIK 2012
- Arnhold, A., Vainio, M., Suni, A. and Jarvikivi, J. (2010). Intonation of Finnish Verbs. In Proceedings of Interspeech 2010.
- Arunima Choudhury & Elsi Kaiser (2012). Prosodic focus in Bangla: A psycholinguistic investigation of production and perception. Linguistic Society of America Annual Meeting, Portland, OR.
- Berger, S., Marquard, C. and Niebuhr, O. (2016). INSPECTing read speech – How different typefaces affect speech prosody. In Proceedings of Speech Prosody 2016, Boston, USA: 514-517.
- Blanchette, F. and Nadeu, M. (2018). Prosody and the meanings of English negative indefinites. Journal of Pragmatics 129: 123-139.
- Chan, K. W. and Hsiao, J. H. (in press). Hemispheric asymmetry in processing low- and high-pass filtered Cantonese speech in tonal and non-tonal language speakers. Language & Cognitive Processes.
- Chang, H.-C., Lee, H.-J., Tzeng, O. J. and Kuo, W.-J. (2014). Implicit Target Substitution and Sequencing for Lexical Tone Production in Chinese: An fMRI Study. PloS one 9(1): e83126.
- Chen, T.-Y. and Tucker, B. V. (2013). Sonorant onset pitch as a perceptual cue of lexical tones in Mandarin. Phonetica 70: 207-239.
- Chen, S.-w. and Tsay, J. (2010). Phonetic realization of suffix vs. non-suffix morphemes in Taiwanese. In Proceedings of Speech Prosody 2010, Chicago.
- Chong, C. S., Kim, J. and Davis, C. (2018). Disgust expressive speech: The acoustic consequences of the facial expression of emotion. Speech Communication 98: 68-72.
- Choudhury, A. and Kaiser, E. (2012). Prosodic focus in Bangla: A psycholinguistic investigation of production and perception. In Proceedings of LSA2012
- Das, K. and Mahanta, S. (2016). Focus marking and Pitch Register modification in Boro. In Proceedings of Speech Prosody 2016, Boston, USA: 864-868.
- Ding, H., Hoffmann, R. and Jokisch, O. (2011). An Investigation of Tone Perception and Production in German Learners of Mandarin. Archives of Acoustics 36(3): 509-518.
- Ding, H., Hoffmann, R. and Hirst, D. (2016). Prosodic Transfer: A Comparison Study of F0 Patterns in L2 English by Chinese Speakers. In Proceedings of Speech Prosody 2016, Boston, USA: 756-760.
- Ding, H., Jokisch, O. and Hoffmann, a. R. (2010). Perception and Production of Mandarin Tones by German Speakers. In Proceedings of Speech Prosody 2010, Chicago
- Franich, K. (2015). The effect of cognitive load on tonal coarticulation. In Proceedings of The 18th International Congress of Phonetic Sciences, Glasgow, UK
- Gieselman, S., Kluender, R. and Caponigro, I. (2011). Pragmatic Processing Factors in Negative Island Contexts. In Proceedings of The thirty-ninth Western Conference On Linguistics (WECOL 2011), Fresno, CA: 65-76.
- Greif, M. (2010). Contrastive Focus in Mandarin Chinese. In Proceedings of Speech Prosody 2010, Chicago.
- Hamlaoui, F. and Makasso, E.-M. (2012). An Experimental Investigation of the Prosodic Expression of Focus and Givenness in Bàsàa Declaratives. Colloque du Réseau Français de Phonologie. Paris.
- Holt, C. M., Lee, K. Y. S., Dowell, R. C. and Vogel, A. P. (2018). Perception of Cantonese Lexical Tones by Pediatric Cochlear Implant Users. Journal of Speech, Language, and Hearing Research 61(1): 174-185.
- Hosono, M. (2010). Scandinavian Object Shift from the Intonational Perspective. In Proceedings of Western Conference On Linguistics, Vancouver, Canada
- Hsieh, F.-f. and Kenstowicz, M. J. (2008). Phonetic knowledge in tonal adaptation: Mandarin and English loanwords in Lhasa Tibetan. Journal of East Asian Linguistics 17: 279-297.
- Hwang, H. K. (2011). Distinct types of focus and wh-question intonation. In Proceedings of The 17th International Congress of Phonetic Sciences, Hong Kong: 922-925.
- Hwang, H. K. (2012). Asymmetries between production, perception and comprehension of focus types in Japanese. In Proceedings of Speech Prosody 2012, Shanghai: 326-329.
- Ito, C. and Kenstowicz, M. (2009). Mandarin Loanwords in Yanbian Korean II: Tones. Language Research 45: 85-109.
- Jörg Peters, Jan Michalsky, Judith Hanssen (2012) Intonatie op de grens van Nederland en Duitsland: Nedersaksisch en Hoogduits. Internationale Neerlandistiek, 50e jaargang, nr.1.
- Kenstowicz, M. (2008). On the Origin of Tonal Classes in Kinande Noun Stems. Studies in African Linguistics 37: 115-151.
- Lai, C. (2012). Response Types and The Prosody of Declaratives. In Proceedings of Speech Prosody 2012, Shanghai.
- Lai, C. (2012). Rises All the Way Up: The Interpretation of Prosody, Discourse Attitudes and Dialogue Structure, University of Pennsylvania.
- Lai, L.-F. and Gooden, S. (2016). Acoustic cues to prosodic boundaries in Yami: A first look. In Proceedings of Speech Prosody 2016, Boston, USA: 624-628.
- Lee, Y.-c. and Nambu, S. (2010). Focus-sensitive operator or focus inducer: always and only. In Proceedings of Interspeech 2010.
- Li, V. G. (2016). Pitching in tone and non-tone second languages: Cantonese, Mandarin and English produced by Mandarin and Cantonese speakers. In Proceedings of Speech Prosody 2016, Boston, USA: 548-552.
- Ling, B. and Liang, J. (2018). The nature of left-and right-dominant sandhi in Shanghai Chinese—Evidence from the effects of speech rate and focus conditions. Lingua.
- Liu, F. (2010). Single vs. double focus in English statements and yes/no questions. In Proceedings of Speech Prosody 2010, Chicago.
- McDonough, J., apos, Loughlin, J. and Cox, C. (2013). An investigation of the three tone system in Tsuut'ina (Dene). Proceedings of Meetings on Acoustics 133: 3571-3571.
- Nambu, S. and Lee, Y.-c. (2010). Phonetic Realization of Second Occurrence Focus in Japanese. In Proceedings of Interspeech 2010
- Ouyang, I. and Kaiser, E. (2012). Focus-marking in a tone language: Prosodic cues in Mandarin Chinese. In Proceedings of LSA2012
- Peters, J., Hanssen, J. and Gussenhoven, C. (2014). The phonetic realization of focus in West Frisian, Low Saxon, High German, and three varieties of Dutch. Journal of Phonetics 46(0): 185-209.
- Sherr-Ziarko, E. (2018). Prosodic properties of formality in conversational Japanese. Journal of the International Phonetic Association: 1-22.
- Shih, S.-h. (2018). On the existence of sonority-driven stress in Gujarati. Phonology 35(2): 327-364.
- Soderstrom, M., Ko, E.-S. and Nevzorova, U. (2011). It's a question? Infants attend differently to yes/no questions and declaratives. Infant Behavior and Development 34(1): 107-110.
- Simard, C., Wegener, C., Lee, A., Chiu, F. and Youngberg, C. (2014). Savosavo word stress: a quantitative analysis. In Proceedings of Speech Prosody 2014, Dublin: 512-514.
- Steinmetzger, K. and Rosen, S. (2015). The role of periodicity in perceiving speech in quiet and in background noise. Journal of the Acoustical Society of America 138(6): 3586-3599.
- Tompkinson, J. and Watt, D. (2018). Assessing the abilities of phonetically untrained listeners to determine pitch and speaker accent in unfamiliar voices. Language and Law= Linguagem e Direito 5(1): 19-37.
- Wong, P. (2012). Acoustic characteristics of three-year-olds' correct and incorrect monosyllabic Mandarin lexical tone productions. Journal of Phonetics 40: 141-151.
- Wu, W. L. (2009). Sentence-final particles in Hong Kong Cantonese: Are they tonal or intonational? In Proceedings of Interspeech 2009.
- Xing, L. and Xiaoxiang, C. (2016). The Acquisition of English Pitch Accents by Mandarin Chinese Speakers as Affected by Boundary Tones. In Proceedings of Speech Prosody 2016, Boston, USA: 956-960.
- Yan, M., Luo, Y. and Inhoff, A. W. (2014). Syllable articulation influences foveal and parafoveal processing of words during the silent reading of Chinese sentences. Journal of Memory and Language 75(0): 93-103.
- Yang, X. and Liang, J. (2012). Declarative and Interrogative Intonations by Brain-damaged Speakers of Uygur and Mandarin Chinese. In Proceedings of Speech Prosody 2012, Shanghai: 286-289.
- Zerbian, S. (2011). Intensity in narrow focus across varieties of South African English. In Proceedings of The 17th International Congress of Phonetic Sciences, Hong Kong: 2268-2271.
- Zhang, J. and Meng, Y. (2016). Structure-dependent tone sandhi in real and nonce disyllables in Shanghai Wu. Journal of Phonetics 54: 169-201.
- Zhang, J. and Liu, J. (2011). Tone Sandhi and Tonal Coarticulation in Tianjin Chinese. Phonetica 68: 161-191.
- Zhang X. A Comparison of Cue-Weighting in the Perception of Prosodic Phrase Boundaries in English and Chinese. PhD dissertation, University of Michigan; 2012.
- Zhao, Y. and Jurafsky, D. (2009). The effect of lexical frequency and Lombard reflex on tone hyperarticulation. Journal of Phonetics 37(2): 231-247.
- Zhu, Y. and Mok, P. P. K. (2016). Intonational Phrasing in a Third Language – The Production of German by Cantonese-English Bilingual Learners. In Proceedings of Speech Prosody 2016, Boston, USA: 751-755.
- 髙橋 康徳 (2012). 上海語変調ピッチ下降部の音声実現と音韻解釈. コーパスに基づく言語学教育研究報告 No. 8, 51-72.
- 王玲、尹巧云、王蓓、刘岩 (2010). 德昂语布雷方言中焦点的韵律编码方式 [Prosodic focus in Bulei dialect of Deang]. Proceedings of The 9th Phonetics Conference of China (PCC2010), Tianjin.
- 尹巧云、王玲、杨文华、王蓓、刘岩 (2010). 德昂语中焦点和疑问语气在语调上的共同编码 [Parallel encoding of focus and interrogative modality in Deang]. Proceedings of The 9th Phonetics Conference of China (PCC2010).
* Before 2012: TimeNormalizeF0.praat
** All the F0 averaging is done on a logarithmic scale: mean_f0 = exp(sum(ln(f01-n)) / n)
*** The velocity profiles of F0 are generated according to:
F0' = (F0sti+1 – F0sti-1) / (ti+1 – ti-1)
which yields the discrete first derivatives of F0. The computation of velocity by every two points is known as central differentiation, and is commonly used in data analysis because of its speed, simplicity, and accuracy ( Bahill, A. T., Kallman, J. S. and Lieberman, J. E. (1982). Frequency limitations of the two-point central difference differentiation algorithm. Biological cybernetics 45: 1-4.)
References
Morton, E. W. (1977). On the occurrence and significance of motivation-structural rules in some bird and mammal sounds. American Naturalist 111: 855-869.
Ohala, J. J. (1984). An ethological perspective on common cross-language utilization of F0 of voice. Phonetica 41: 1-16.
Yi's other tools