FormantPro is a convenient tool built for large-scale, systematic experimental studies of formant movements. It allows users to obtain continuous formant and formant velocity trajectories from multiple sound files, take various measurements, and save them in formats ready for graphical and statistical analysis. It also generates averaged trajectories and measurements across repetitions and speakers. More specifically, FormantPro allows you to:
Get continuous trajectories of F1, F2, F3 and F2_3, using Praat’s built-in “To Formant (burg)...” function, where F2_3 = mean (F2, F3) is a joint indicator of tongue frontness
Get continuous formant velocity (= first derivative of continuous formant) curves using a central differentiation algorithm (for labeled intervals only);
Manually segment and label intervals for each sound (.wav) file;
Cycle through all sound files in a folder without using menu commands;
Get time-normalized formant (for labeled intervals only) and formant velocity trajectories. Useful if you want to plot these curves averaged across multiple repetitions of the same word or sentence;
Get the actutime corresponding to each of the time-normalized formant and formant velocity points. Useful if you want to plot these curves with averaged real time for each interval;
Get maxformant, minformant, meanformant, maxformantvelocity, duration and meanintensity from each labeled interval;
Get results in ensemble files (files containing values from all the sounds in a folder): normformant.txt, normIntensity, formantvelocity.txt, maxformant.txt, minformant.txt, meanformant.txt, maxformantvelocity.txt, duration.txt and meanintensity.txt;
Get mean_normformant.txt, which contains meanformant trajectories averaged across repetitions of identical sentences;
Get mean_normformant_cross_speaker.txt, which contains meanformant trajectories averaged across identical sentences produced by multiple speakers.
Instructions
Put _FormantPro.praat in the folder containing the sound files to be analyzed, and launch Praat;
Select Open Praat Script... from the top menu;
Locate _FormantPro.praat in the dialogue window and select it;
When the script window opens in Praat, select Run from the Run menu (or type the key shortcut command-r or control-r);
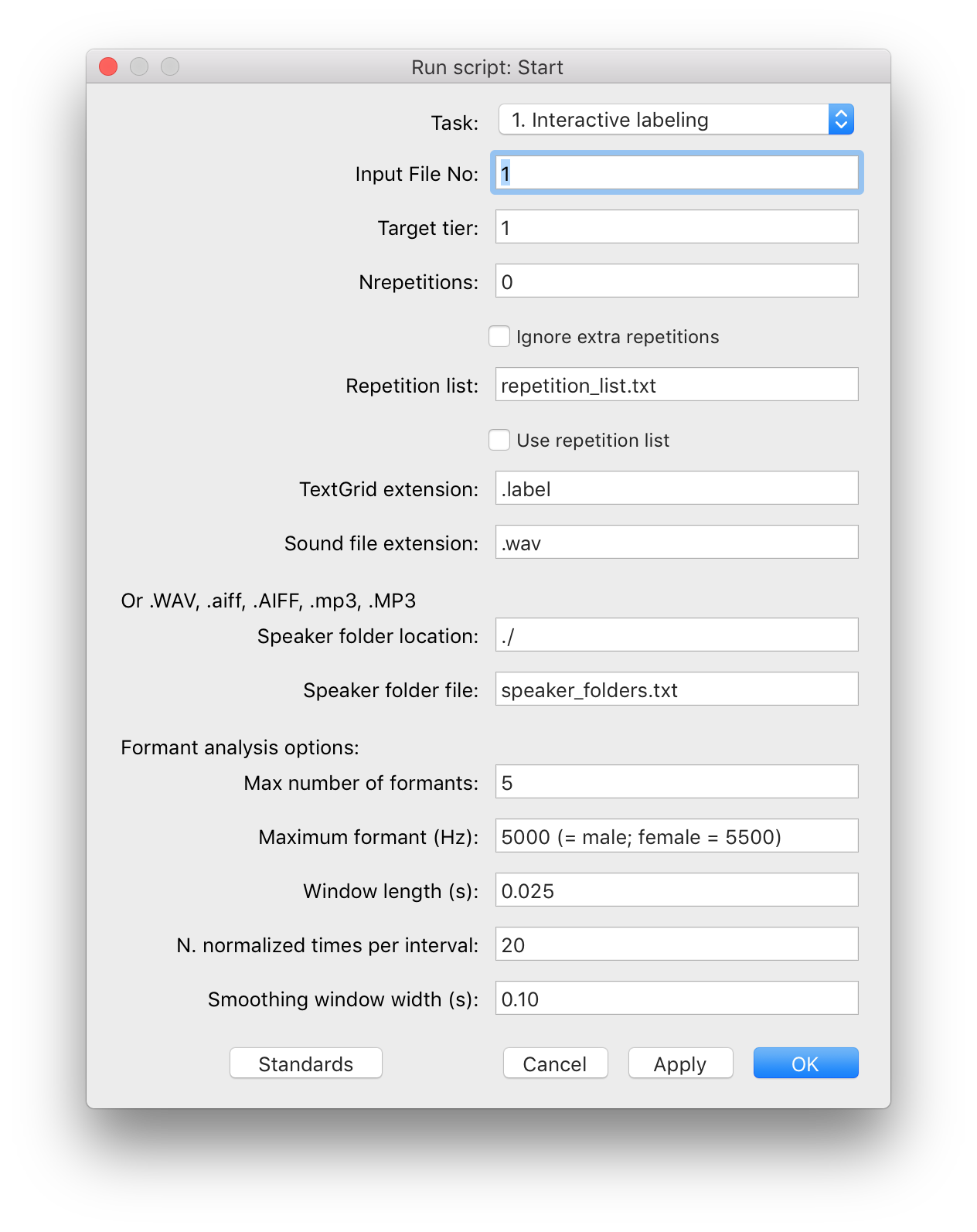
In the "Start" window, check or uncheck the boxes according to your need, and set appropriate values* in the text fields or simply use the default values. Select the task by checking the appropriate radio button.
Click OK and two windows will appear. The first window (TextGrid) displays the waveform and spectrogram of the current sound together with optional pitch track and formant tracks in the spectrogram panel. (These tracks cannot be manually changed. So you can hide them to reduce processing time by using the corresponding menu.)
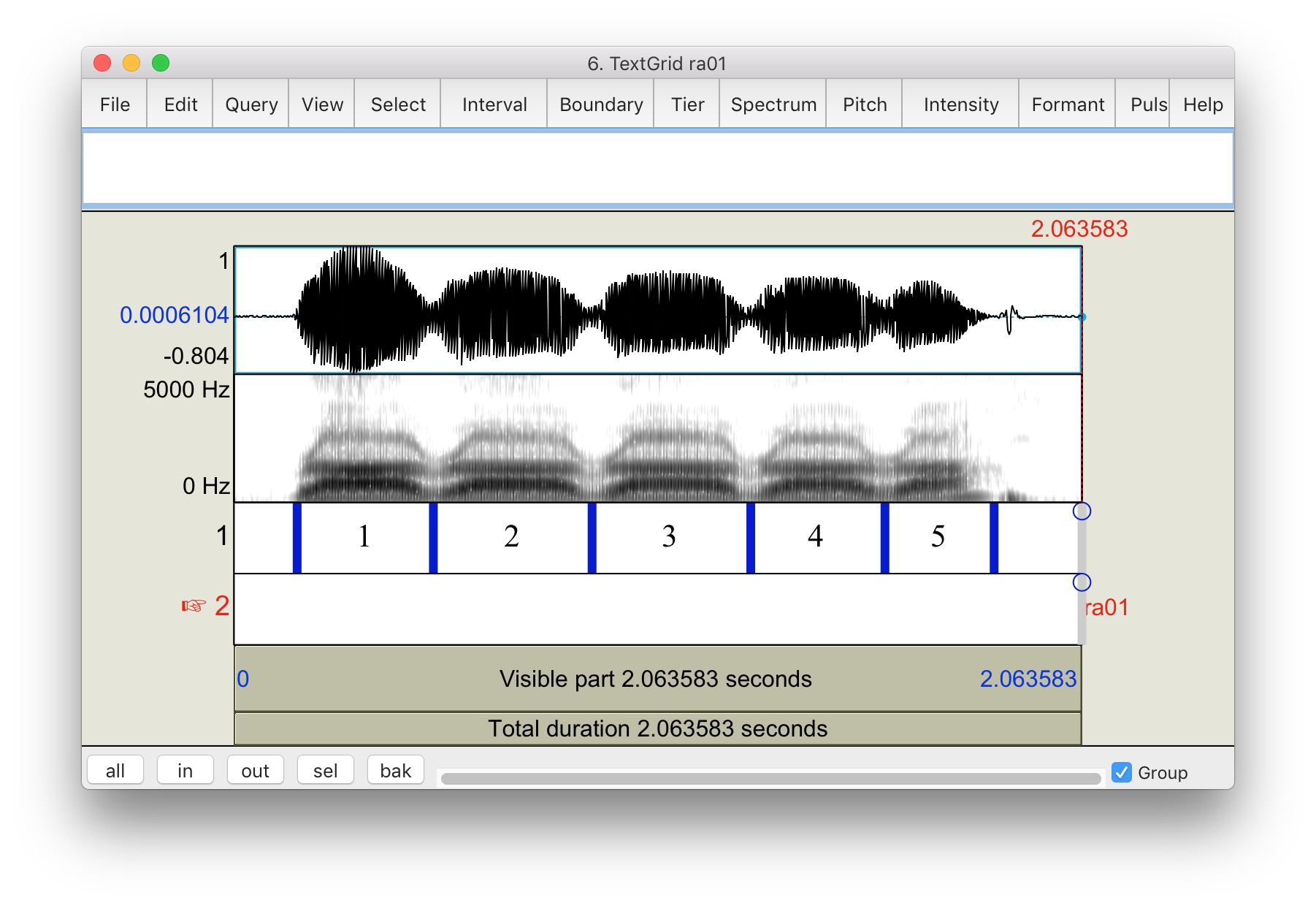
At the bottom of this window are two TextGrid tiers, where you can insert interval boundaries (Tier 1) and add comments (Tier 2). For any interval that you want to have results saved, a label in Tier 1 is required. The label can be as simple as a, b, c or 1, 2, 3.
The second window (Pause) allows you to control the progress of the analysis. To bring up the next sound to be analyzed, press "Next". To go back to previous sound, press “Back”. To jump to any sound, type the number in the “Jump to” textbox and “Jump”. Pressing all these three buttons will also automatically save all the measurements of the current sound.
To end the current analysis session, press "Done" in the Pause window, and the name of the last sound analyzed will be shown in the Info window. You can use that number as a starting point in you next analysis session. To exit without saving any data, press “Stop”.
After processing individual files, you can run the script again to get ensemble files by checking the third radio button from the top.
You can also change various parameter after processing individual files by runing the script again with the radio button "Process all sounds without pause" checked. The script will run through all the files on its own.
You can also generate mean formant and formant velocity trajectories averaged across repetitions of identical sentences. To do this, set the value of Nrepetitions in the opening window according to the number of repetitions in your data set when you run the script with the "Get ensemble files" button checked. Make sure that the number of labeled intervals are identical across the repetitions.
To force _FormantPro to skip extra repetitions, you need to check "Ignore extra repetition" and also name your sound files with a final digit that indicates repetition.
To average across unequal number of repetitions, you can create a text file (default = repetition_list.txt) in which sound-file names are listed in a single column, with blank lines separating the repetition groups. You can create this file by renaming "FileList.txt" that is always generated by FormantPro, and then modifying it by inserting blank lines and deleting sounds that you want to exclude. Note that deleting sound names in this file allows you to skip sounds that you want to exclude in your final analysis.
You can also generate mean normf0 trajectories averaged across speakers. To do this, put a copy of FormantPro in the folder above all the folders containing data from individual speakers. Then create a text file (speaker_folders.txt) containing the speaker folder names arranged in a single column. Now run _FormantPro with the 4th task--Average across speakers--checked. The script will read time-normalized ensember files from all the speaker folders, average the values and then save them in cross-speaker ensemble files. In the Start window, you also need to tell _FormantPro where the speaker folder file is. The default location is the current directory: "./". If it is in an upper directory, you should enter "../"
Each time you press "Continue" in the Pause window, various analysis results are saved for the current sound as text files:
X.formant (Hz) -- formant in real time scale, obtained with Praat command "To Formant (burge)..." and smoothed with a trimming algorithm (Xu, 1999) and a triagular filter
X.normtime_formant (Hz) -- time-normalized continuous formant trajectory. The trajectory in each interval is divided into the same number of points (default = 20). The time scale is the original, except that the onset time of interval 1 is set to 0.
X.normtime_barkformant (bark) -- time-normalized formant in bark scale.
X.formant_velocity (Hz/s) -- velocity profile (instantaneous rates of formant change) of corresponding formant trajectory.
X.formantmeans -- Containing the following values (in the order of the columns):
meanF1, meanF2, meanF3 (Hz)
maxF1, maxF2, maxF3 (Hz)
minF1, minF2, minF3 (Hz)
maxV1, maxV2, maxV3 (Hz/s)
duration (ms)
mean intensity (dB)
After the analysis of all the individual sound files are done, you can gather the analysis results into a number of ensemble files by running the script again and checking the button "Get ensemble results" in the startup window. The following ensemble files will be saved:
formant.txt (Hz)
formantvelocity.txt (Hz/s)
normtime_formant.txt (Hz)
normtime_barkformant.txt (bark)
normtime_formantvelocity.txt (Hz/s)
norm_actutime.txt (s)
maxformant.txt (Hz)
minformant.txt (Hz)
meanformant.txt (Hz)
duration.txt (ms)
maxformantvelocity.txt (Hz/s)
meanintensity.txt (dB)
If Nrepetitions > 0, the following files will also be saved:
mean_normformant.txt (Hz)
mean_normtime_formant.txt (Hz)
mean_normtime_barkformant.txt (bark)
mean_normtime_formantvelocity.txt (Hz/s)
mean_norm_actutime.txt (s)
mean_maxformant.txt (Hz)
mean_minformant.txt (Hz)
mean_meanformant.txt (Hz)
mean_duration.txt (ms)
mean_maxformantvelocity.txt (Hz/s)
mean_meanintensity.txt (dB)
If Task 4 "Average across speakers" is selected, the following file will also be saved:
mean_normtime_formant_cross_speaker.txt
mean_normtime_barkformant_cross_speaker.txt
mean_normtime_formantvelocity_cross_speaker.txt
mean_norm_actutime_cross_speaker.txt
Note that you can generate the ensemble files only if you have analyzed at least one sound following the steps described earlier.
About time-normalization
Time-normalization is the process of taking the same number of data points from an interval at an even distance, regardless of the duration of the interval.
Time-normalized trajectories are meant only for graphical comparisons. Measurements suitable statistical analysis, such as maxformant, minformant, meanformant, etc., are taken from non-time-normalized trajectories.
Because the same number of equidistant points are taken from each interval, time-normalization allows the averaging of formant trajectories across repetitions and even speakers. This process not only evens out most of the random variations, but also allows graphical presentations of large amount of data.
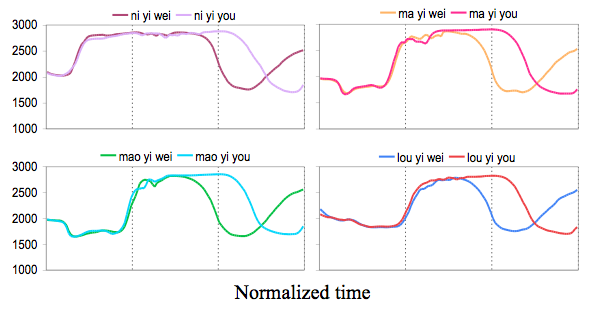
A further advantage of time-normalization is that it allows the user to clearly see the locations and manners of the maximum differences between experimental conditions by plotting the mean formant trajectories in overlaid graphs, like those shown below. This in turn allows user to find measurements that potentially best reflect the real differences between experimental conditions.
In contrast, in the common practice of reporting only specific measurements, one can never be sure what the rest of formant trajectories might look like.
Finally, it should be noted that the common practice of reporting only one or two measurements from a syllable or word is also a kind of time-normalization, except that it is done at a very low time resolution. The default time resolution in FormantPro, in contrast, is 20-points per interval.
Examples
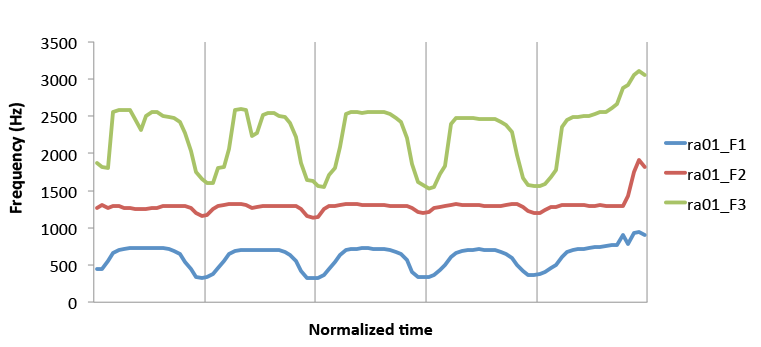
The following examples show how functional contrasts can be easily brought out by time-normalized mean formant trajectories.
_ _
Figure 6 of Xu (2007): Mean formant curves [(F2+F3)/2] of trisyllabic Mandarin phrases, averaged across 10 repetitions by a male speaker.
 _ _
_ _