How children learn to talk
- Learning to talk is to learn to control one's own articulators to generate acoustic patterns that are heard as proper speech.
- Children presumably achieve this by mimicking mature speakers. But they cannot see most of the articulatory movements to be learned, because those are hidden.
- So they have to rely on what they can hear, and learn by repeatedly adjusting their own articulation until they sound like the target speaker.
- This hypothetical auditory-guided articulatory-based vocal learning may seem simplistic, but it has a clear theoretical advantage, i.e., there is no need for learners to worry about how much their own articulators are different from those of the target speakers.
- Learners can just keep adjusting their articulation until their acoustic output cannot be made any closer to the target utterance. Regardless of the remaining differences, their articulation may already sound like that of the target speakers.
Simulation of AAVL
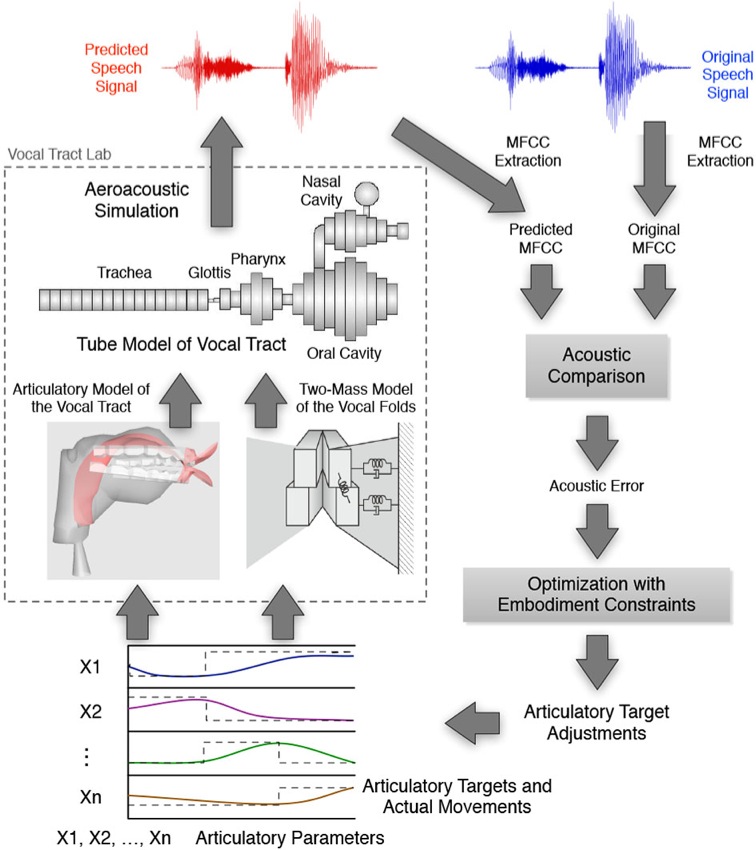
AAVL can be tested, by computationally simulating all the critical components of the learning process (see also the flow chart):
- An articulatory synthesizer (e.g., VocalTractLab) that emulates
- anatomic structures of the articuatory system (middle left)
- aerodynamics of acoustic signal generation
- basic dynamics of articulatory movements (lower left)
- Mimicry of children's vocal learning strategy (right):
- Acoustic patterns (MFCC) of the learner's utterances are repeatedly compared with that of the target utterance, without normalizing their vocal tract dimensions;
- In each trial a full set of articulatory targets are randomly generated by VocalTractLab;
- Articulatory targets that produce better matches than before are temporarily retained, while others are disgarded;
- The learning is deemed successful once there is a clear convergence toward an acoustic pattern that sounds like the target utterance.
- There is no need for an exact match of either acoustic or articulatory parameters.
- The simulation can be used as a tool for testing theories of speech learning as well as normal production: Each of the element listed above may represent a particular theoretical conjecture that can be tested.
- It may also lead to the next generation of speech synthesis.